How To Not Train Your Dragon: Training-free Embodied Object Goal Navigation with Semantic Frontiers
Abstract:
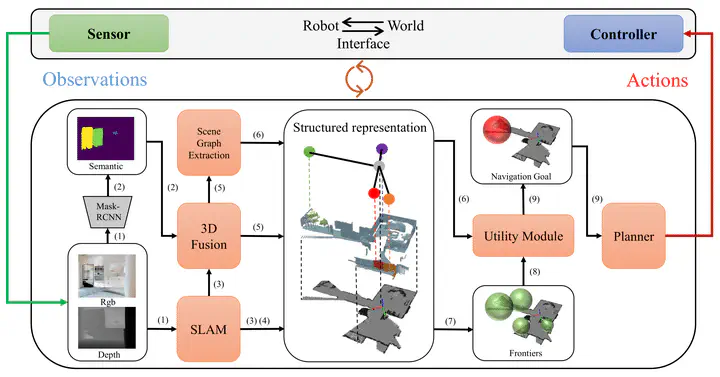
Object goal navigation is an important problem in Embodied AI that involves guiding the agent to navigate to an instance of the object category in an unknown environment— typically an indoor scene. Unfortunately, current state-of-the-art methods to this problem rely heavily on data-driven approaches, e.g., end-to-end reinforcement learning, imitation learning, and others. Moreover, such methods are typically costly to train and hard to debug, leading to a lack of transferability and explainability. Inspired by recent successes in combining classical and learning methods, we present a modular and training-free solution, which further embraces more classic approaches, to tackle the object goal navigation problem. Specifically, our method builds a structured scene representation based on classic visual simultaneous localization and mapping (V-SLAM) framework and reasons about promising areas to search goal object by injecting semantics to geometric-based frontier exploration. Our structured scene representation is composed of 2D occupancy map, semantic point cloud, and spatial scene graph. Semantic knowledge is introduced to the geometric frontiers by propagating semantics on the scene graphs with language-based prior from large-scale foundation models and scene prior from scene statistics. With injected semantic priors, the agent is capable of reasoning the most promising frontier to explore. The proposed pipeline shows strong experimental results for object navigation on the Gibson benchmark dataset, outperforming the previous state-of-the-art. We also perform comprehensive ablation studies to identify the current bottleneck in the object navigation task. Our software package is implemented that includes ROS support, hence easily deployable on real robots.